Is it all over for filmmakers?
Another month and another model update accompanied by a massive amount of marketing, Linkedin spam, spin, and dubious claims.
Two years ago I debunked claims that Sora would destroy filmmaking. It’s still mostly garbage today. Last year I punished myself by testing Google's Veo model every day for a month. I am still recovering from the AI slop induced nausea.
Last week’s new model was a version 2.0 update of Bytedance’s Seedance video generator. As always, one has the feeling that lies are travelling around the world twice before the truth has time to put its shoes on. So here I am for another debunk.
One of the most talked about demos of the Seedance 2.0 model was a fight scene depicting Tom Cruise and Brad Pitt (two fight scenes if we count the costume changes). The claims by the news outlets and on social media were that an Irish filmmaker typed just two lines into Seedance 2.0 and 30 seconds later a full formed fight scene with multiple angles was generated.

“Extraordinary claims require extraordinary evidence” - Carl Sagan
The usual villainy on LinkedIn drowned the site with the video along with the claims that “Hollywood was over”. As shown in the past these are often code words for ‘Jews must go’ because they never talk about any other country’s film industry like that.
Imagine if the anti-Semites on LinkedIn decided one morning to be racist to the Chinese. Their posts would read like this:
'Google just released Veo 4.5 and it is a game changer! Hengdian World Studios is shaking in their boots! The Chinese film industry is about to be cooked!’
You'd condemn that language because it is less coded and more obviously racist. You'd openly say that is an attack on millions of hard working Chinese people working in the Chinese media industry.
Because of that LinkedIn has become a highly toxic environment full of unqualified AI meddlers who are paid to post hyperbole. What usually happens is that an AI company releases a new model. They give sample videos to marketing companies who then send the samples to influencers with a script for social media that usually reads ‘Hollywood is over. I generated this full scene with with just two prompts. What used to cost $20,000,000 now costs pennies. This is a game changer that democratises filmmaking!’
LinkedIn is really something.
Then there’s the list of claims that self-anointed experts and salesmen make which inevitably lead to disappointment.
If any of these people knew anything about filmmaking then they’d know that filmmaking was democratised many years ago starting with the earliest portable cameras down to the modern day smartphone which now has a sensor that can capture better quality images than the cameras used to film ‘The Blair Watch Project’. Yet despite everyone owning a high resolution video camera now, how many great filmmakers are there? For every 25 million people who own a smartphone there is only one who can shoot a film like Left-Handed Girl (shot entirely on an iPhone). Filmmaking is not just about democratising technology. One has to learn every aspect of the craft, push themselves to create original stories and then have the taste to execute the story to high standards.
So when you ask those AI influencers to prove they generated the demos they either refuse to reply or they respond with ‘Sorry I no longer have access because I lost the password’ and other similar excuses. So whenever you see a popular AI video demo by an influencer ask them:
1. For the prompts so you can test them yourself.
2. For a live demonstration.
3. Behind the scenes workflow.
If they shy away from transparency it is because they were given the demo by the AI company and that a lot more work was needed to make the demo than just 'prompting'.
So I had to call bogus on this immediately. After a lifetime of shooting in college, in film school, being on sets and running post-production; and after years of deep dives into every new piece of technology and testing all the cloud and local AI models, the claims being made immediately rubbed me up the wrong way. Other demos of the Seedance model had the usual errors we have come to expect from AI video generators.

Badly rendered Chinese writing that means nothing. Errors and low quality outlines everywhere.
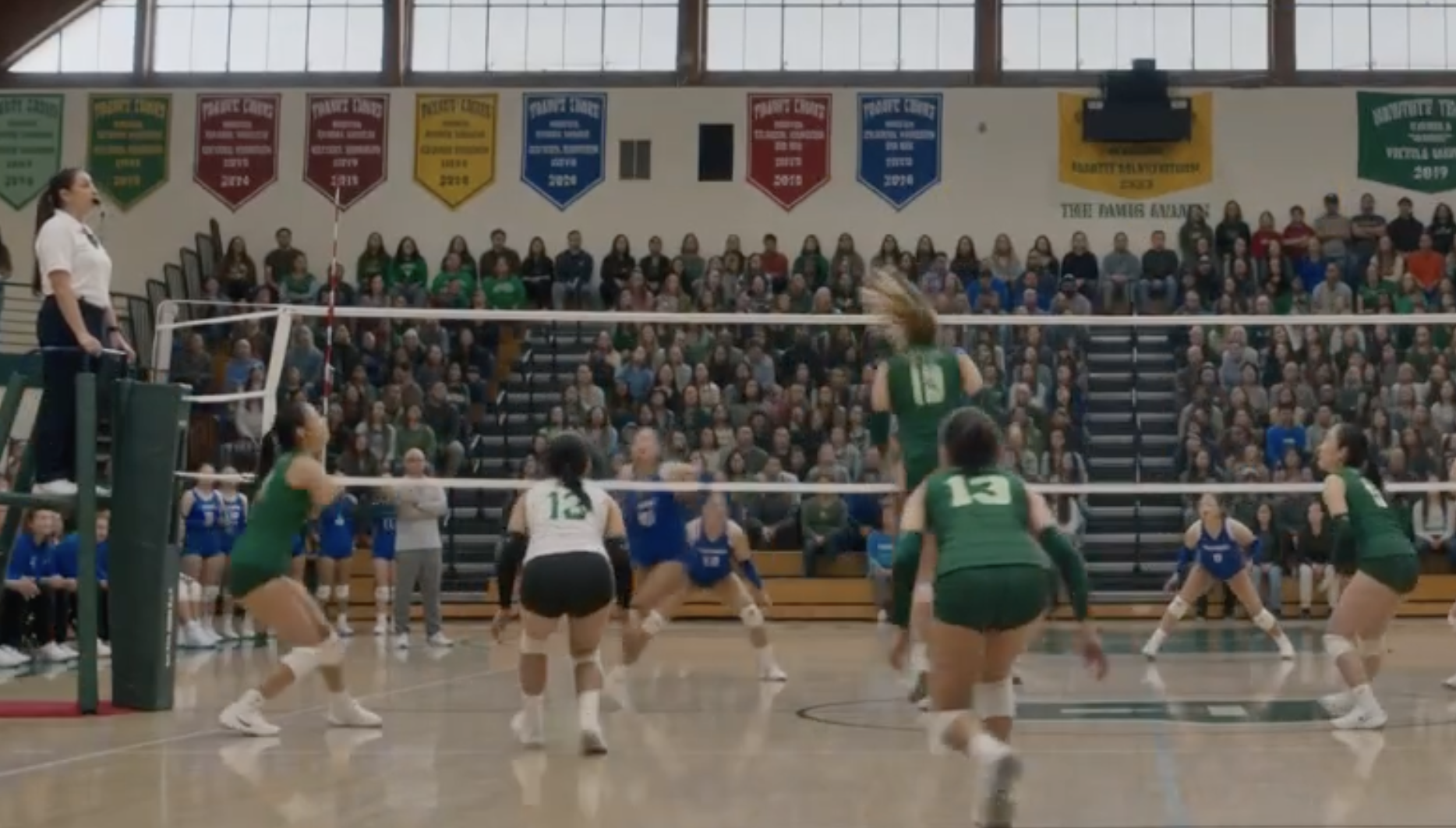
There are three number 13s playing for one team and one of them is wearing inverted colours. The net doesn’t have a net.

It’s supposed to be Japanese writing but it’s gibberish. There’s a boy in a white t-shirt whose feet point the wrong way.

In the generated video of a pianist, the position of his hands don’t match the higher pitched keys being played.
Very readable text

When there’s a group of people close together the same expression is rendered on all of them, gibberish writing and signage is common, inconsistencies in the architecture, errors such as the incomplete Walkman strap.

A demo labelled ‘Impressive Realism’ had lawns that extend to the road, no kerbs and cars parked on the lawns.

A man returns home. His apartment number is 219 and it is next to apartment 023. Every door in the hallway has a random design.

He inserts a key into his door that already has (deformed) keys in it.
I was pretty sure what we were looking at was a bog standard video to video workflow (with image references of Tom Cruise and Brad Pitt provided for face replacement and consistency) because we can see the camera movement and AI video generators are really bad at simulating realistic camera moves, especially handheld shaky cam. Sure, the Seedance 2.0 model is newer and thus more reliable, but it was highly unlikely that just two prompts and thirty seconds were needed to generate a full multi-angle fight scene.
I hopped over to Seedance’s website and it only took 10 seconds to find green screen footage of two stuntmen performing the same style of fight choreography we see in the Cruise vs Pitt scene. Seedance had used green screen footage for a different demo - this time using a prompt for an anime style fight scene.

I duly let LinkedIn know about my findings and posted the video below showing the green screen footage next to the AI fight scene.
Some more green screen footage showed up on a Chinese news site along with another fight video generated from the stunt performers.

Bytedance probably recorded a large library of green screen footage for training and guidance.

The same Wing Chun/Jun Fan gung-fu style choreography makes an appearance with different characters.
It’s important to note that not anyone could shoot the green screen video above. Video to video requires excellent input/source material for best results, as Seedance did. Hiring a green screen studio, stuntmen, choreographer, lighting crew and cameraman would cost a couple of grand a day on the low end. Then there is the cost of generating. We don’t yet know how often Seedance users will have unusable output. The discard rate in generative media tends to be very high. By unusable we mean 'not good enough for the big screen’ where regular errors and artefacts ruin the viewing experience.
One other thing irks me about the generated fight scene. Pitt and Cruise are pulling their punches and sometimes acting hit when there is a clear missed punch. That’s something actors and stuntmen have to do to avoid hurting each other, but in a purely AI generated video that shouldn’t be a thing. A hit should always be a very clearly visible hit.
Here’s another Seedance 2.0 fighting video that “leaked” (almost all the leaks are fighting videos as if generated fights is what the film industry and martial arts fans have always asked for). The timing, movement and distancing of the fighters is similar to the previous examples above and again the punches are being pulled:
All the demos so far have used generic prompts such as ‘two men fighting’ which means the output relies heavily on the training material. It will be interesting to see how much a user can control the fight choreography with prompts only. I suspect the fixed video length of generated footage will be an issue. If the limit is 7 seconds or 15 seconds then the model has to squeeze everything within that window, which almost always results in the model not following instructions accurately.
Notice in the UFC fight demo that well known corporate logos in the background are generated quite well, but all other text and logos are deformed because the output is dependent on the training data and references. When the model is left to fill the gaps errors occur.
So was the input really just a 2 line prompt or was it actually 2 lines, green screen video footage, and references too? The evidence appears to show that stuntmen were filmed from several angles, that a clip had to be generated for every angle, and then finally all clips were stitched together for marketing. Only Seedance knows. Some people who have had early access have been open about what they are doing…
We should also bear in mind that even if a user doesn’t upload a green screen video reference (because obviously Robinson didn't shoot any), Seedance could have been using green screen video references in the background to help guide the output. We have evidence they did shoot on green screen with the same style choreography. They could have a whole library of green screen footage on their servers to assist in generating fight scenes. (more about that in the Addendum below)
It’s still remarkable that after two years of video to video people are still unable to recognise it and we still have journalistic malpractice whenever a new AI model is released. The Corridor Crew guys have been demonstrating video to video and AI face replacement for many years now.
Here’s a generated fake trailer I made in early 2024 (almost two years ago) featuring a similar technique. If it looks impressive you’re being tricked by it. It’s just a series of stills from John Woo films, reskinned with an AI model, the AI errors cleaned up in Photoshop, then a few seconds of motion is added to each still frame, titling and credits added in After Effects, and a soundtrack generated in Udio (which has very dodgy badly pronounced Cantonese).
Did I go around saying Hong Kong cinema is toast? Of course not. Many of the same issues generative media suffers from today were slightly worse back then. The biggest change since has been the introduction of talking characters.
There will always be AI fan boys online who will read my breakdowns and say “But look where it was two years ago. Imagine where it will be in six months!”. This is a ‘Number Go Up’ fallacy that has often been used by cryptocurrency fanatics and religious extremists when they point at their growth and claim that they will own the world in the future, because they fundamentally don’t know how the world works. In the case of AI fan boys they also don’t know how the technology works and that for exponential improvement to occur they would need exponential amounts of data, compute, energy and memory alongside incredibly difficult software engineering.
But they will keep shifting the goal posts anyway. Before they used to say ‘Wait six months’. Now they say ‘What do you think it will look like in 10 years?’
Of course generative media (that’s the proper term, not ‘AI filmmaking’) and generative VFX will continue to improve, but we need to remind ourselves why audiences flock to cinemas, buy discs and merchandise, and travel across the country or the world to meet actors and filmmakers at conventions and ceremonies. Tom Cruise often risks his life to entertain us and he’s the biggest star in the world because of it. Physical talent and celebrity matters to fans and followers. That’s why the Seedance fight demo above had to use the faces of two celebrities for wide reach and hype. Without that it would have just been two stuntmen and an AI filter. Nothing to talk about.
Similarly, if physical talent and celebrity didn’t matter spectators wouldn’t spend extraordinary amounts of money and time following their favourite athletes and sports teams. They would be content replacing real sports with video games alone. But that’s not how the world works. Humans, like all animals, are social creatures who need to belong to something bigger than themselves. If we don’t look up to people who achieved greatness with physical hard work, persistence and raw talent then we will lose our sources of inspiration. Hierarchy gives humanity something to strive for. Flat societies are artificially enforced by dictators and theocrats and they become violent because they suppress the creative mind and the desire to express oneself freely.
The entertainment industry (sports, film, acting, music, literature and art) is largely controlled by agencies for that reason - for onboarding and managing the talent that audiences look up to. Film production companies and studios come and go, but the agencies run the show.
If AI guys ever manage to make a somewhat decent full movie they're going to be in for a non-surprise when they see their movie being pirated on torrents because almost nobody wants to pay money to watch an mpeg made with next to no effort or minimum effort.
The only generative media enthusiasts who will have success will be those who hire skilled production professionals, writers and actors, and even then they will need to show behind the scenes production workflows. Audiences want evidence of investment, hard work and talent.
So in conclusion, is it over for filmmakers and is “Hollywood cooked”? Even if the fight scenes coming out of Seedance were genuinely generated with prompts only the model still produces tons of errors in the form of illegible gibberish text, morphing people, low quality details in the background, and other typical AI errors throughout the video content. It seems that this model is more optimised for motion rather than fixing all the known issues that plague video generators.
That makes Seedance 2.0 useless for the motion picture industry unless you need a quick dirty plate for VFX, a quick dirty B-roll clip, or lowish quality content for social media.
I look forward to testing Seedance myself, probably via ComfyUI so I can control the output better. I’m interested in seeing how cleanly it handles video to video and if it can do variations from a single input source. I will be checking to see how well it can handle detailed fight choreography instructions instead of just ‘two men fighting on a roof’ because then I’ll be able to tell if the model is receiving guidance from a pre-recorded video source or not.
Addendum:
This blog post has been read by many thousands of people around the world. Things get lost in translation whenever too many people speak at the same time and some of them are not tech savvy. So some clarifications below.
Robinson uploaded more clips to YouTube that has more constume and character changes, but featuring the same kind of fight choreography. I won’t believe these were from prompts alone until I try it myself. There have been too many let downs in the past.
The replies to his video upload feature the standard toxic hate speech towards “Hollywood” with no regard for the thousands of workers worldwide who earn a living from every single movie produced.

Some people seem to be confused by what I said. They are assuming Robinson uploaded green screen footage. As shown elsewhere, the green screen footage is from Bytedance’s library which they could be using to guide the models output without the user’s knowledge. In fact, we know that Bytedance’s new generation of models can fetch references. Here’s an example of how the Seedream 5.0 (Seedance’s little brother) image generator can fetch external data (on the web or a server) for references, something that until now models didn’t do automatically.

There’s also another misinterpretation. Some people assume that using the green screen footage is a form of “cheating” or “AI scam”. It should not be seen that way. Human performances should be used as input for generative media. That’s a win-win situation where skilled performers and actors are employed and the AI models help craft characters and scenes, all of which should be cleaned up and edited by VFX artists and editors.
I don’t write against the use of AI. I write against the hyperbole and toxic language surrounding AI. The idea that AI can do anything and everything without human guidance and will take over all jobs is toxic, nihilist, hyperbolic and factually incorrect.
Finally, I was interviewed by Newsweek here. I was slightly misquoted in the article because they had to compress all the quotes. For example, I didn’t make the claim that Robinson said the fight video was generated in 30 seconds. That claim came from this video I linked to.
Here is the full Newsweek interview:
1) What was your first thought when you saw the video, and what drove you to debunk it so thoroughly?
The video was being widely shared on LinkedIn by people who have no experience in film production, CGI or even generative media. Sometimes these are fake accounts created by marketing firms. Whenever a new model drops they always declare that the new model spells doom for filmmakers, photographers, actors, artists, and so on.
My first thought was ‘Ah, this looks like another video to video workflow’.
Sketch to image, image to image, image to video and video to video are now the most common workflows in generative media production. Seedance’s site calls it ‘Reference to Video’ (R2V). Basically the concept is that the contours of shapes in the input video help guide the AI model to produce more predictable and reliable output. Prompts are used alongside the input media to describe what is in the scene itself.
So I went to Seedance’s website and immediately saw that they used live action green screen footage as inputs for some of their demos. They made no secret of this so they are not to blame for any deceptive marketing. In fact, I often speak with engineers at AI companies and these guys are very honest, hard working and open about the limitations of the models. It is the marketing firms and influencers who have a tendency to overhype the abilities of AI models.
I’m pretty sure that Bytedance will be optimising Seedance for action scenes because martial arts are native to Chinese culture and popular worldwide, but for best results they will need video to video workflows like they demonstrate several times on Seedance’s website.
2) Can you tell me more about your background with film and your experience with AI? How existential do you think AI really is to Hollywood?
I studied drama, literature and film production in my youth with an eye to writing and directing films but because my parents raised me in the fashion industry I ended up mostly working in photographic and video production for the fashion industry rather than film. But the production skills, equipment, applications and workflow are the same.
Over the years we have seen stories that AI would destroy photography jobs and replace photography and video in the fashion industry. I have consistently debunked these ideas in public and in-house company communications. AI models do not know what new products look like without photos being taken in the first place, and consumers demand that photos show products authentically (even when retouched). If fashion imagery isn’t accurate that can result in sales dropping badly or an increase in refunds.
My predictions turned out to be true. AI has not destroyed photography. At most we are now seeing generative images being used to compliment photography. For example, in Photoshop we use Adobe Firefly’s Generative Fill tool to remove creases or to extend backgrounds. We are also seeing image to video being used - this adds one or two seconds of motion to a photograph. None of this is perfect though. The AI output often requires manual clean up.
3) What frustrates you most about the conversation/hype around AI?
As mentioned above the marketing is toxic. It’s a form of hate speech that frequently attacks working people who have bills to pay and families to feed. Many workers, even in the digital creative field, are not technologically savvy so they become demoralised easily by toxic overhyped marketing.
4) Your post went pretty viral - did Ruairi Robinson respond to you at all? Have you heard from anyone notable about it?
Robinson’s comments were irrelevant because they were not new. He was parroting an old line and influencers quoting him were producing clickbait.
5) Anything else you'd like Newsweek readers to know?
The output of the best AI models today are far below the very high requirements of media production. They might look impressive for 7 seconds on a little phone screen, but a full length 120 minute long movie on a big TV or cinema screen is a completely different thing. You can make a two hour long AI movie today, but you’ll have to cut a lot of corners, accept a lot of errors in the images, accept the video compression is very high, and accept that only a tiny percentage of AI/tech die hards will have the patience to sit through it or even pay for it.
Despite what AI fanatics say your readers, consumers and customers matter. They’re the ones who decide what will be successful or not. If they believe articles, books, comics, films and music were made with minimal to no effort then they will give you less attention and less money for it. Consumers aren’t the zombies some people claim they are. Just because they enjoy some cheap clothing, some fast food and unlimited streaming doesn’t mean they want everything to become quickly produced and quickly consumed junk.
Audiences and martial arts fans are not asking for generated fight scenes. They’re asking for more of this…